
The research pipeline is not linear
Last post I sold you on worker-critic pairs as the elegant core of the architecture.
But I think the writer pair is kinda bad?
The diminishing returns of scientific paper writing
“The last 20% of a paper takes 80% of the time” is a phrase I heard constantly in grad school. For instance, say you start a difference-in-differences paper on immigration enforcement. The first stretch flies: you code the main spec, the point estimate goes the right way, you’re already sketching the intro in your head. Somewhere around the halfway mark of the time you’ll eventually spend, you have something that genuinely looks like 80% of a paper.
Then you hit the flat part of the curve.
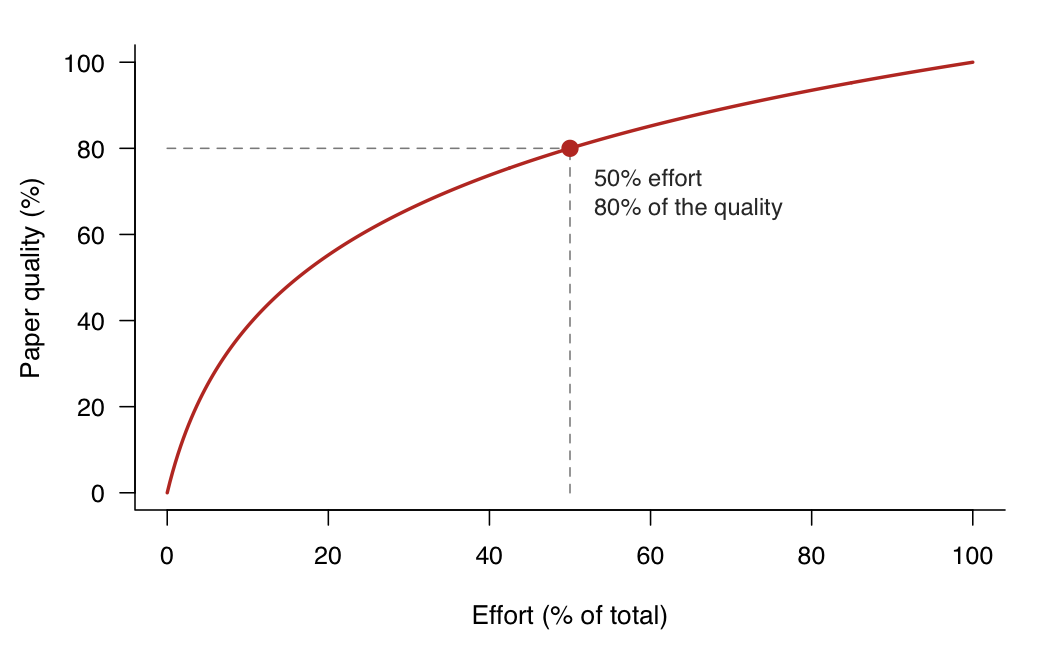
We spend half of the time pushing the first draft, the other half fine-tuning.
This is where the fine-tuning hell lives. You need to read several times the introduction to check if it is under the proper narrative. The mechanism section has to be tight and requires a back-and-forth approach, especially if you have co-authors. Economists rewrite sections endlessly to find that sweet spot.
None of this should be new to anyone who’s written a paper in grad school or under a tenure clock. So what does it have to do with AI?
Context rot is a thing
Context rot is something you probably noticed using AI in long sessions. Language models, once a session accumulates enough context, stop reliably using what’s in the conversation and drift back toward their generic priors.
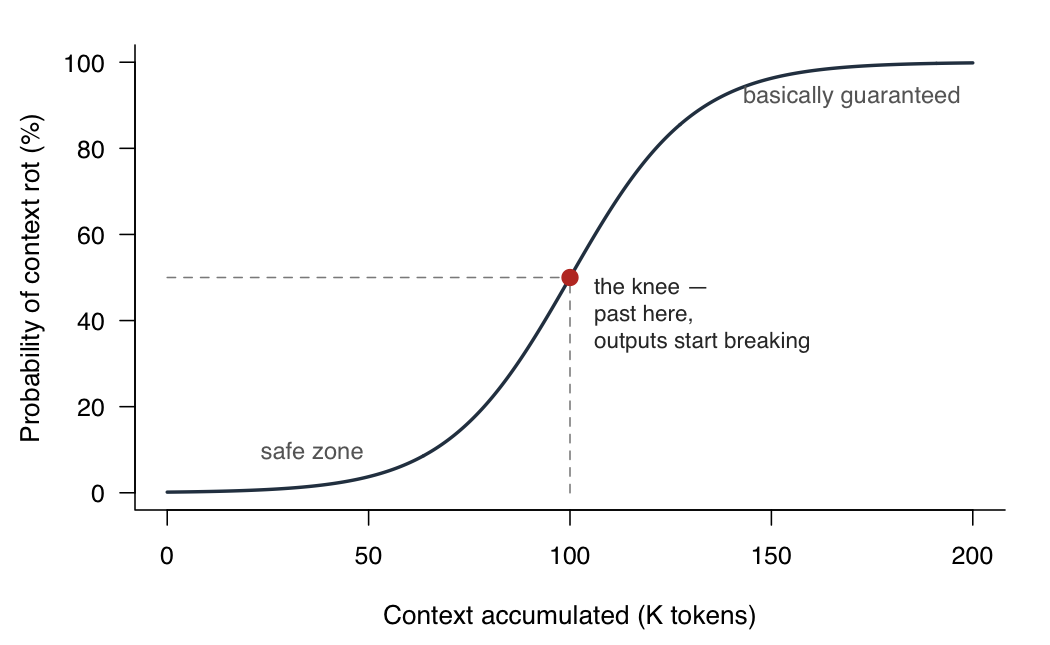
Roughly the shape of the degradation.
This has been measured — see RULER and Chroma’s context-rot evals — and the usual fix is session hygiene. Short sessions with scoped tasks. Say you want to generate the first block of code for your results section. In your current session, ask Claude to write a task document: the spec, the data, the expected output, something like a to-do. Then start a new session, point it at the document, and have it dispatch the coder-critic pair. You dodge context rot because Claude has no memory across sessions — it starts fresh every time, reading only the document.
The writer carries everyone else’s context
Session hygiene works beautifully for the librarian, the coder, the theorist. Each of them has a scoped job. The librarian queries a literature. The coder reads a spec and a test file. The theorist works a derivation that fits in one session. None of them needs to know what the others are doing to do its own job. Writing the perfect Python Callaway-Sant’Anna code only requires a well-written data dictionary.
Well, the writer can’t. Writing a paper is synthesis at its core. By definition, the paper is where all the other aspects of the research are glued together. You can’t draft a paragraph of the introduction without all of it loaded. The writer needs the union of every other agent’s context.
By the time you’ve done the lit review, cleaned the data, run the analysis, and written the theory section, the accumulated context is enormous. The scope grew, the narrative’s demands grew with it, and there’s no task document small enough to paper over the problem.
Look back at the rot curve. The early agents live comfortably in the safe zone. I feel like the writer has a hard time finding its safe zone. It starts somewhere in “basically guaranteed” and works from there.
The writer-critic
I do not believe AI can truly emulate the writing of a human. Even if you add several papers for it to draw inspiration from, you end up seeing more of an “above-average” output than the sweet spot you are looking for.
So, in that sense, how can the critic actually criticize something that it cannot properly comprehend?
The critic, left to its own devices, is never satisfied — it can always find another angle, another concern, another suggestion, another tone. And because prose has no ground truth, the writer has no way to push back and say no, this is actually fine. So the writer does what writers do under pressure: it adds. It adds hedges. It adds qualifying clauses. By pass three the paragraph is technically responsive to every critic note and is also probably worse than pass one.
Here’s what it looks like in the wild. On a working paper I’m co-authoring, an AI-drafted conclusion opened like this (note how subtle and annoying this actually is):
…, we find that the intervention reshapes the distribution of outcomes, leading to economically meaningful declines along two primary margins, with little effect on two others…
You cannot deny it is written well. It is a simple paragraph giving the conclusion of our findings. But if you grab your academic magnifying glass and look between the words, you will see that this paragraph is mediocre. It does not sell anything properly. So my coauthor pulled the plug and proposed a draft himself:
… we find that the intervention reduces two of our four primary margins by roughly 10 percent each, with no effect on the remaining two…
It is the same text, but better. Specific numbers where the draft had “economically meaningful declines.” “No effect” where the draft had “little effect.” The writer pair couldn’t produce this version because its critic wouldn’t let it — anything specific gets flagged as “potentially overstated,” anything direct gets softened to hedge the downside. The local optimum of the loop is defensive prose.
I am not sure if this is related completely to context rot. But it seems that the pair has a hard time writing like me because well… They are machines with a very limited memory, and memorizing their own rules, my own tone, and the proper context of the project is a herculean task for them.
The sweet spot is an interior solution
Let us go back to the production function of a paper. Assume a classic log form for quality as a function of effort:
\[Q(e) = \alpha \log(1 + k \cdot e)\]concave, with diminishing returns — the 80/20 curve from the first figure. Now layer in context rot. Let $R(c)$ be the probability of rot at context level $c$ — the sigmoid from the second figure. The reliability rate, $1 - R(c)$, is the fraction of what the AI produces that you can actually trust.
Under AI-assisted work, the usable quality is the production function scaled by reliability:
\[Q_{\text{AI}}(e, c) = Q(e) \cdot \bigl(1 - R(c)\bigr)\]In a perfect AI-assisted world, $R(c) = 0$ and paper production becomes fully automated. In an imperfect world, $Q_{\text{AI}}(e, c) < Q(e)$ at some point when $R(c) > 0$.
Human intervention, then, is the gap between what’s achievable and what AI delivers:
\[H(e, c) = Q(e) - Q_{\text{AI}}(e, c) = Q(e) \cdot R(c)\]Early in the project, $R(c) \approx 0$ and $H \approx 0$ — you barely touch it. Late in the project, $R(c) \to 1$ and $H \to Q(e)$ — the human is doing essentially everything. In between, you have an interior solution: a non-zero mix of AI and human at every point in the project.
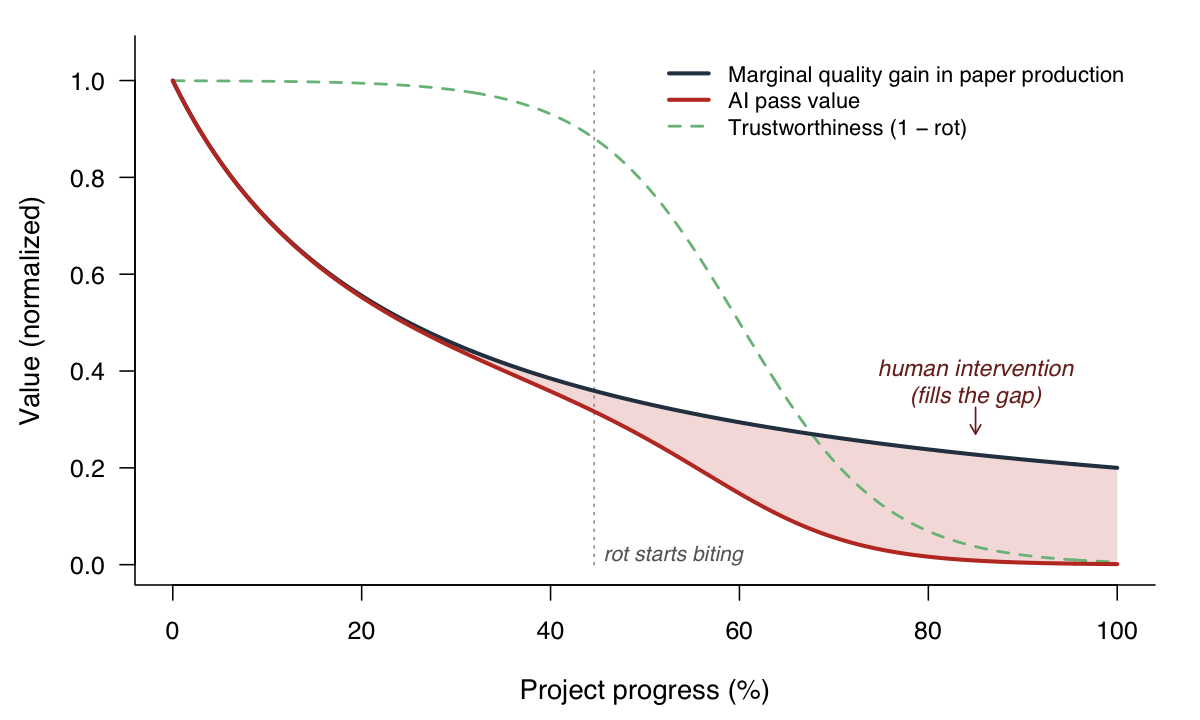
The gap between the two curves is where human intervention has to fill in. Early, the curves overlap — AI does almost everything. Past the rot knee, the gap opens and widens.
This isn’t just the writer-critic problem, by the way. AI tooling lives under its own production constraints — context limits, generic priors, no ground truth for prose. For the coder, the sweet spot is wide: run the pair in a loop until the tests pass. For the writer, the sweet spot is narrow: one draft, maybe one critic pass, then the human.
The asymmetry isn’t accidental. Software engineering has a quiet structural advantage most people never name: the critic has a ground truth. Does the code compile? Does the test pass? Does the output match the expected value? The coder-critic can hammer on a function for a hundred iterations and you trust the hundredth pass more than the first, because every pass runs against the same external verifier. The loop converges because there’s something outside the loop pulling it toward a fixed point.
Prose has no verifier. A paragraph is better or worse by the judgment of whoever reads it next — and that judgment isn’t stable across readers, editors, referees, or even the author three days later. When the critic flags a sentence as “potentially overstated,” there’s no test to run to check whether it actually is. You’re left with two LLMs arguing in a courtroom with no judge, each confident, neither correctable, the paragraph getting steadily more defensive.
This is why software engineers have automated much more of their pipeline than empirical academics can, and it’s not because AI writes code better than it writes prose (maybe they do). It’s because the domain itself has an external arbiter. Tests, compilers, the whole automated-verification stack that runs on every commit — that’s the unsung infrastructure of software’s AI story. A research paper has none of that.
What I learned
I built the architecture believing in a symmetry of quality. The production function isn’t constant across phases. The coder-critic sits in a wide sweet spot — it can run on autopilot until the tests pass, precisely because the tests exist. The writer-critic sits in a narrow one and spends most of its life on the wrong end of the rot curve, precisely because no analogous test exists.
What I’m doing now is letting the writer-critic run once, maybe twice, and then pulling the plug. I basically use the text generated as a template and rewrite everything from scratch. The next version of the scaffold will probably make that asymmetry explicit — different loops for different phases, with the writer pair on the shortest leash.
If you’re an economist tinkering with something similar, I’d love to hear what you’ve tried — open an issue on the repo or email me.