
Last post I sold you on worker-critic pairs as the elegant core of the architecture.
But I think the writer pair is kinda bad?
The diminishing returns of scientific paper writing#
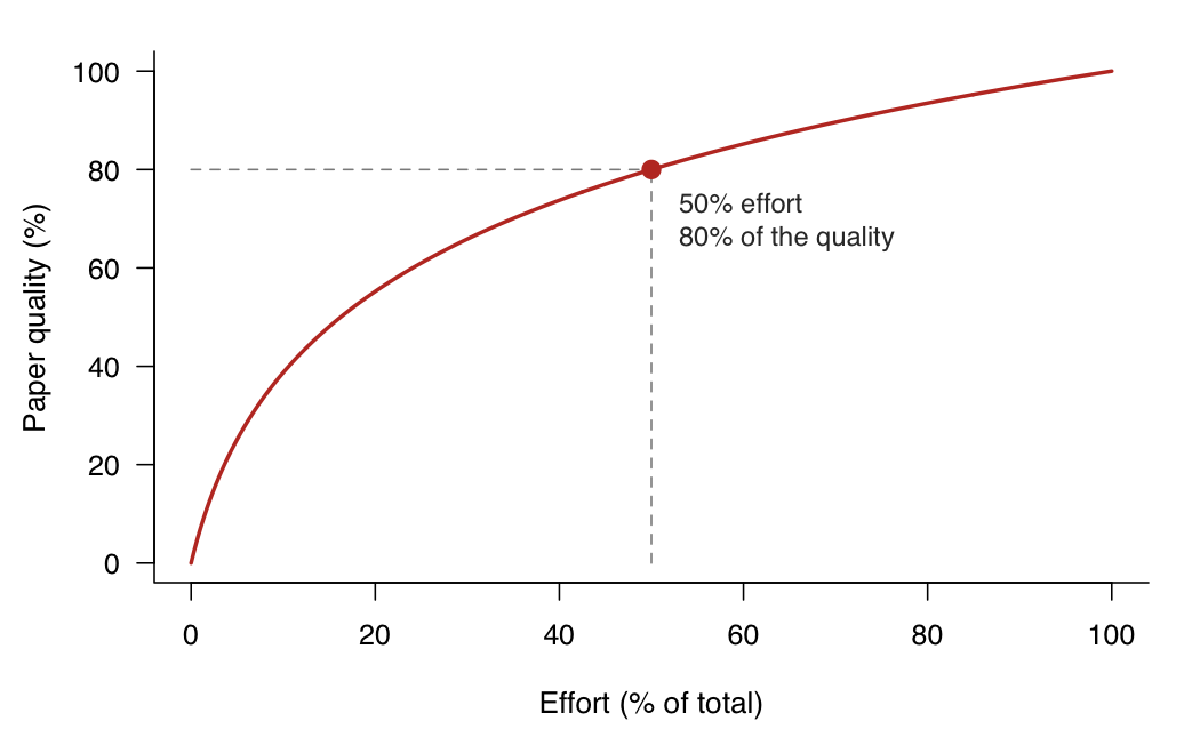
“The last 20% of a paper takes 80% of the time” is a phrase I heard constantly in grad school. For instance, say you start a difference-in-differences paper on immigration enforcement. The first stretch flies: you code the main spec, the point estimate goes the right way, you’re already sketching the intro in your head. Somewhere around the halfway mark of the time you’ll eventually spend, you have something that genuinely looks like 80% of a paper.
Then you hit the flat part of the curve.
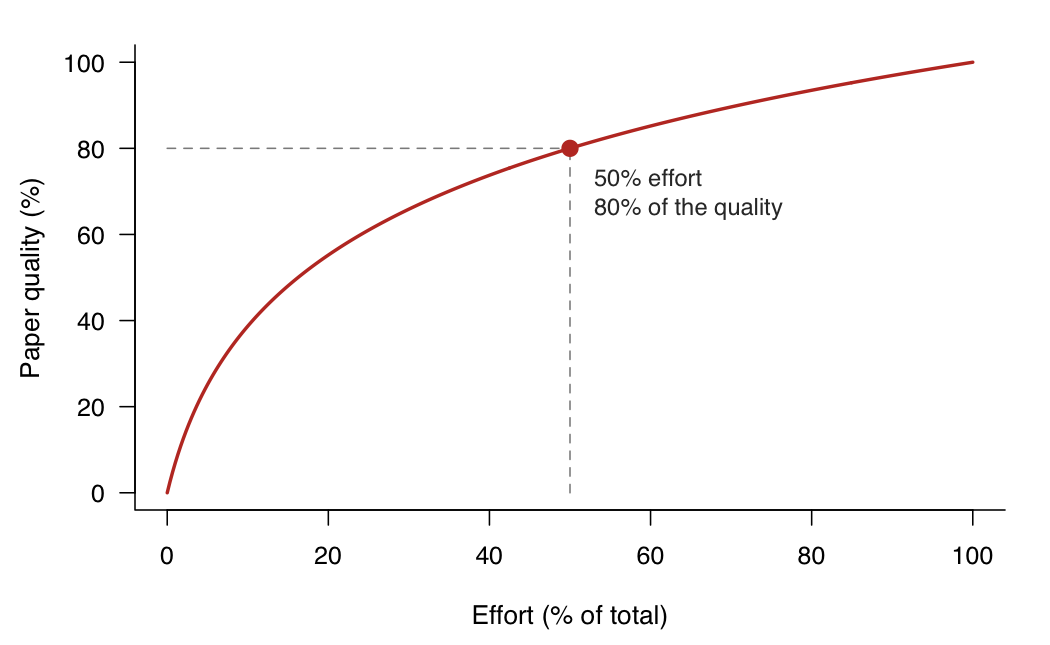
We spend half of the time pushing the first draft, the other half fine-tuning.
This is where the fine-tuning hell lives. You need to read several times the introduction to check if it is under the proper narrative. The mechanism section has to be tight and requires a back-and-forth approach, especially if you have co-authors. Economists rewrite sections endlessly to find that sweet spot.
None of this should be new to anyone who’s written a paper in grad school or under a tenure clock. So what does it have to do with AI?
Context rot is a thing#
Context rot is something you probably noticed using AI in long sessions. Language models, once a session accumulates enough context, stop reliably using what’s in the conversation and drift back toward their generic priors.
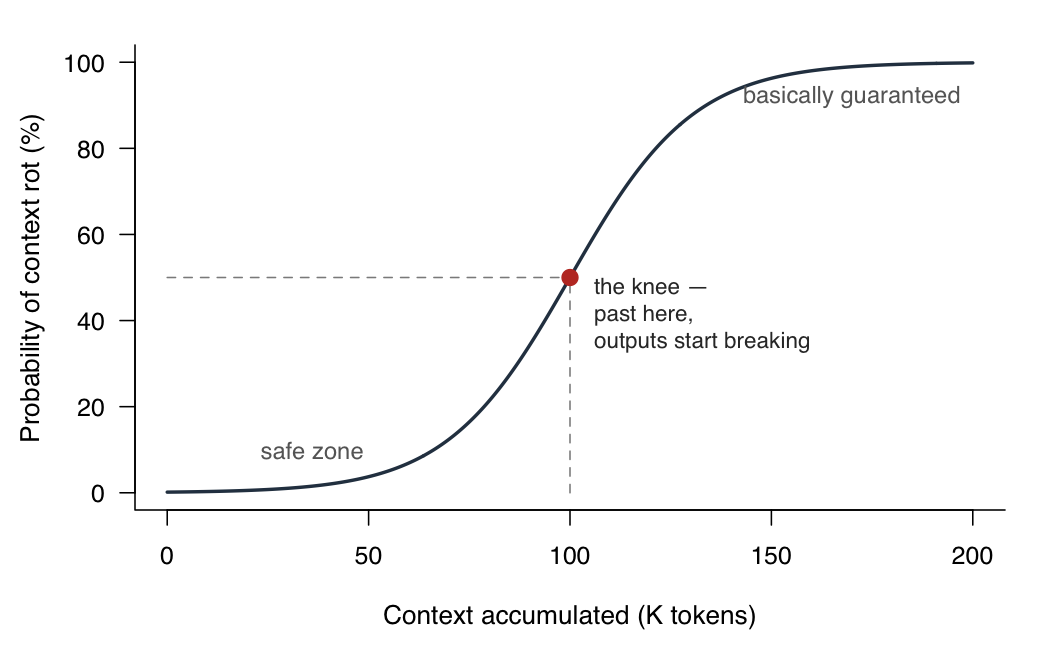
Roughly the shape of the degradation.
This has been measured — see RULER and Chroma’s context-rot evals — and the usual fix is session hygiene. Short sessions with scoped tasks. Say you want to generate the first block of code for your results section. In your current session, ask Claude to write a task document: the spec, the data, the expected output, something like a to-do. Then start a new session, point it at the document, and have it dispatch the coder-critic pair. You dodge context rot because Claude has no memory across sessions — it starts fresh every time, reading only the document.
The writer carries everyone else’s context#
Session hygiene works beautifully for the librarian, the coder, the theorist. Each of them has a scoped job. The librarian queries a literature. The coder reads a spec and a test file. The theorist works a derivation that fits in one session. None of them needs to know what the others are doing to do its own job.
Well, the writer can’t. Writing a paper is synthesis at its core. By definition, the paper is where all the other aspects of the research are glued together. You can’t draft a paragraph of the introduction without all of it loaded. The writer needs the union of every other agent’s context.
The sweet spot is an interior solution#
Let us go back to the production function of a paper. Assume a classic log form for quality as a function of effort:
$$Q(e) = \alpha \log(1 + k \cdot e)$$concave, with diminishing returns. Now layer in context rot. Let $R(c)$ be the probability of rot at context level $c$. Under AI-assisted work, the usable quality is the production function scaled by reliability:
$$Q_{\text{AI}}(e, c) = Q(e) \cdot \bigl(1 - R(c)\bigr)$$Human intervention is the gap:
$$H(e, c) = Q(e) - Q_{\text{AI}}(e, c) = Q(e) \cdot R(c)$$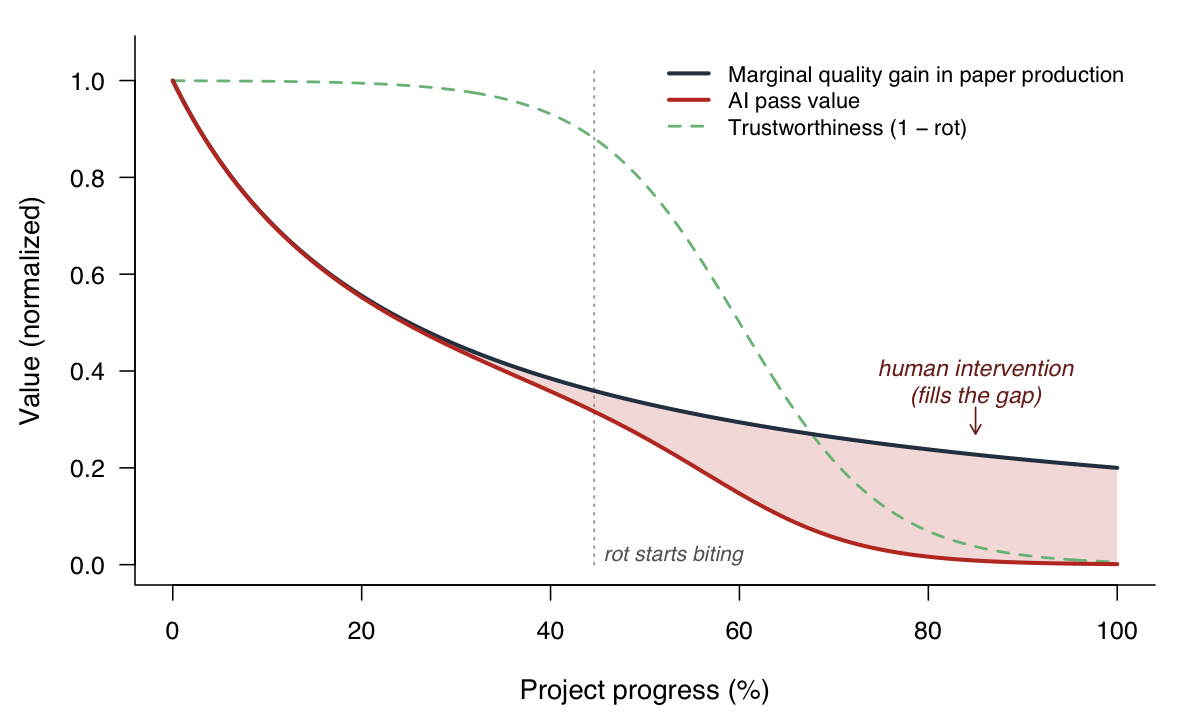
The gap between the two curves is where human intervention has to fill in.
What I learned#
The coder-critic sits in a wide sweet spot — it can run on autopilot until the tests pass, precisely because the tests exist. The writer-critic sits in a narrow one and spends most of its life on the wrong end of the rot curve, precisely because no analogous test exists.
What I’m doing now is letting the writer-critic run once, maybe twice, and then pulling the plug.